
-l # 显示详情信息(权限、大小、修改时间等)
-a # 显示隐藏文件
CSP-S
1.1 基础知识与编程环境
1.1.1 linux
常用命令
ls:获取当前文件夹内文件名
pwd:显示当前绝对路径
cd:跳转目录
mkdir:创建目录
-p # 创建多层目录
tree:用树形结构展示目录和文件
rm:删除目录或文件
-r # 递归删除
cp:复制文件或目录
mv:移动文件或目录
g++:编译cpp文件
-o 可执行文件名
-O2/3/1 优化代码
-w 不生成警告
-Wall 生成所有警告
time:查看命令运行时间
real表示的是整个过程的实际经过时间。user表示的是用户空间中的代码执行所花费的 CPU 时间。sys表示的是内核空间中的代码执行所花费的 CPU 时间。
echo:用于显示文本或变量的值
2.1 STL模板
常用函数
2.1.1 set
用于维护一个有唯一元素的集合。
insert(元素): 插入一个元素。
erase(元素): 删除一个元素。
find(元素): 查找一个元素。(如果等于.end()则没有此元素)
size(): 返回容器中元素的数量。
empty(): 检查容器是否为空。
2.1.2 multiset
与set相似,维护一个可以相同的元素集合。
2.1.3 queue
先进先出。
empty(): 检查队列是否为空。
size(): 返回队列中的元素数量。
front(): 返回队首元素的引用。
back(): 返回队尾元素的引用。
push(): 在队尾添加一个元素。
pop(): 移除队首元素。
2.1.4 deque
双端队列。
front():返回第一个元素。
back():返回最后一个元素。
begin():返回第一个元素的迭代器。
end():返回最后一个元素的迭代器。
empty(): 检查队列是否为空。
size(): 返回队列中的元素数量。
clear():清空。
insert(iterator pos,value) :在pos位置插入value元素。
push_back(value):在队尾添加value。
push_front(value):在队头添加value。
pop_back():删除队尾元素.
pop_front():删除队头元素
2.1.5 priority_queue
优先队列。
priority_queue<int> pq;
priority_queue<int,vector<int> > pq; // 大根堆
priority_queue<int,vector<int>,greater<int>> pq; // 小根堆
empty(): 检查队列是否为空。
size(): 返回队列中的元素数量。
top(): 返回队列顶部的元素(不删除它)。
push(): 向队列添加一个元素。
pop(): 移除队列顶部的元素。
2.1.6 map
字典,用于存储键值对。
map<key_type, value_type> mp;
mp[key]=value:赋值
mp[key]:查看元素
empty(): 检查是否为空。
size(): 返回元素数量。
clear():清空map。
2.1.7 multimap
与map相似,可存储相同键值对。
2.1.8 bitset
优化bool数组使用。
bitset<N> b;
b[i]获取i位bool值。
count():返回 1 的个数。
size():返回位数。
test(pos):检查某一位是否为 1。
all():检查是否所有位都为 1。
any():检查是否有任何一位为 1。
none():检查是否所有位都为 0。
&:按位与
|:按位或
^:按位异或
~:按位取反
2.2 数据结构
2.2.1 树
概念
空树:没有节点的树。
节点的度:一个节点还有的子树的个数。
树的度:一棵树中,最大节点的度。
叶节点:度为0的节点。
父节点、子节点、兄弟节点
二叉树:树的度为二的树
完全二叉树:除了最下层,其余饱满
满二叉树:每层都饱满
性质
二叉树第$i$层节点数最多:$2^{n-1}$ $(i\geq1)$
深度为$k$的二叉树最多有$2^k-1$个节点$(k\geq1)$
满二叉树节点数:$2^k-1$ $(k\geq1)$
遍历
先序遍历:根左右
中序遍历:左根右
后序遍历:左右根
2.2.2 并查集
查找两个元素是否在同一集合。
int fa[N];
void init(){for(int i-1;i<=n;i++)fa[i]=i;} // 初始时所有节点的父节点都是自己
int get(int x){
if(fa[x]==x)return x;
return fa[x]=get(fa[x]); // 把子节点换成兄弟节点,这样优化
}
void add(int x,int y){
int xf = get(y),yf = get(z);
if(xf==yf)return ;
fa[xf]=yf;
}
2.2.3 线段树
区间修改,区间查询。注意懒标记
ll n,m,a[N],f[4*N],g[4*N],op,x,y,z;
// 开4倍数组
void init(ll l,ll r,ll rt){ // 给定a[i],生成一颗线段树
if(l==r){
f[rt] = a[l];
return ;
}
ll mid = (l+r)>>1;
init(l,mid,rt<<1);
init(mid+1,r,(rt<<1)+1);
f[rt]=f[rt<<1] + f[(rt<<1)+1];
}
ll get(ll x,ll y,ll l,ll r,ll rt){ // 查找x~y的和
if(l>=x and r<=y){
return f[rt];
}
ll mid = (l+r)>>1,ans=0;
if(g[rt]){ // 懒标记
f[rt<<1] += g[rt]*(mid-l+1);
g[rt<<1] += g[rt];
f[(rt<<1)+1] += g[rt]*(r-mid);
g[(rt<<1)+1] += g[rt];
g[rt] = 0;
}
f[rt] = f[rt<<1]+f[(rt<<1)+1];
if(x<=mid) ans+=get(x,y,l,mid,rt<<1);
if(y>mid) ans+=get(x,y,mid+1,r,(rt<<1)+1);
return ans;
}
void add(ll x,ll y,ll num,ll l,ll r,ll rt){ // 在x~y之间每一个数加上z
if(l>=x and r<=y){
f[rt]+=num*(r-l+1);
g[rt] += num;
return ;
}
ll mid = (l+r)>>1;
if(g[rt]){ // 懒标记
f[rt<<1] += g[rt]*(mid-l+1);
g[rt<<1] += g[rt];
f[(rt<<1)+1] += g[rt]*(r-mid);
g[(rt<<1)+1] += g[rt];
g[rt] = 0;
}
if(x<=mid) add(x,y,num,l,mid,rt<<1);
if(y>mid) add(x,y,num,mid+1,r,(rt<<1)+1);
f[rt] = f[rt<<1]+f[(rt<<1)+1];
return ;
}
2.2.4 字典树 Trie
处理查询字符串

2.2.5 笛卡尔树
同时满足堆的性质和二叉搜索树的性质(中序遍历)。时间复杂度$O(n)$
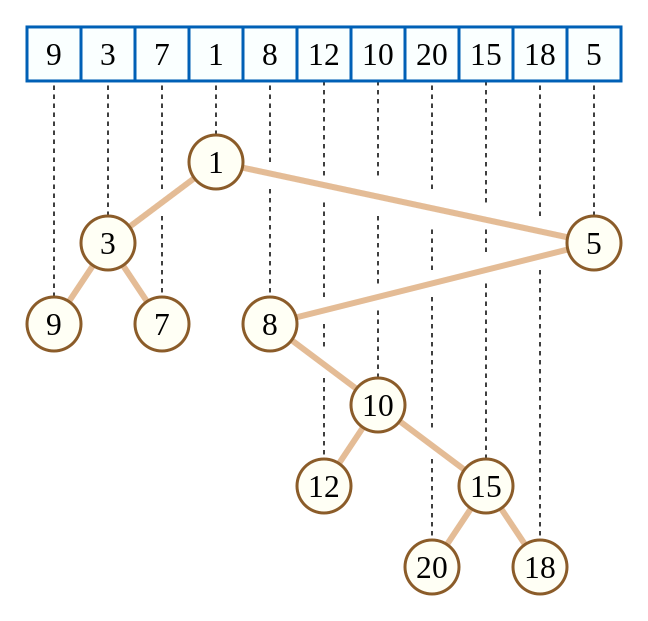
2.2.6 二叉搜索树
二叉搜索树是一种二叉树的树形数据结构。对于一个节点,左子树小于节点小于右子树(反过来也可以)。所以它的中序遍历相当于对数组排序。
插入操作:将要插入元素向下递归对比,比当前节点小就遍历左子树,大就遍历右子树直到没有子节点,将元素加入到下面。
查询操作:和插入操作一样向下遍历,直到与待查找元素相同。
删除叶子节点操作:直接删除。
删除非叶子节点:将左子树的最大节点或右子树的最小节点与待删除节点交换,删除交换后的叶子节点。
时间复杂度$O(\log_2n) - O(n)$
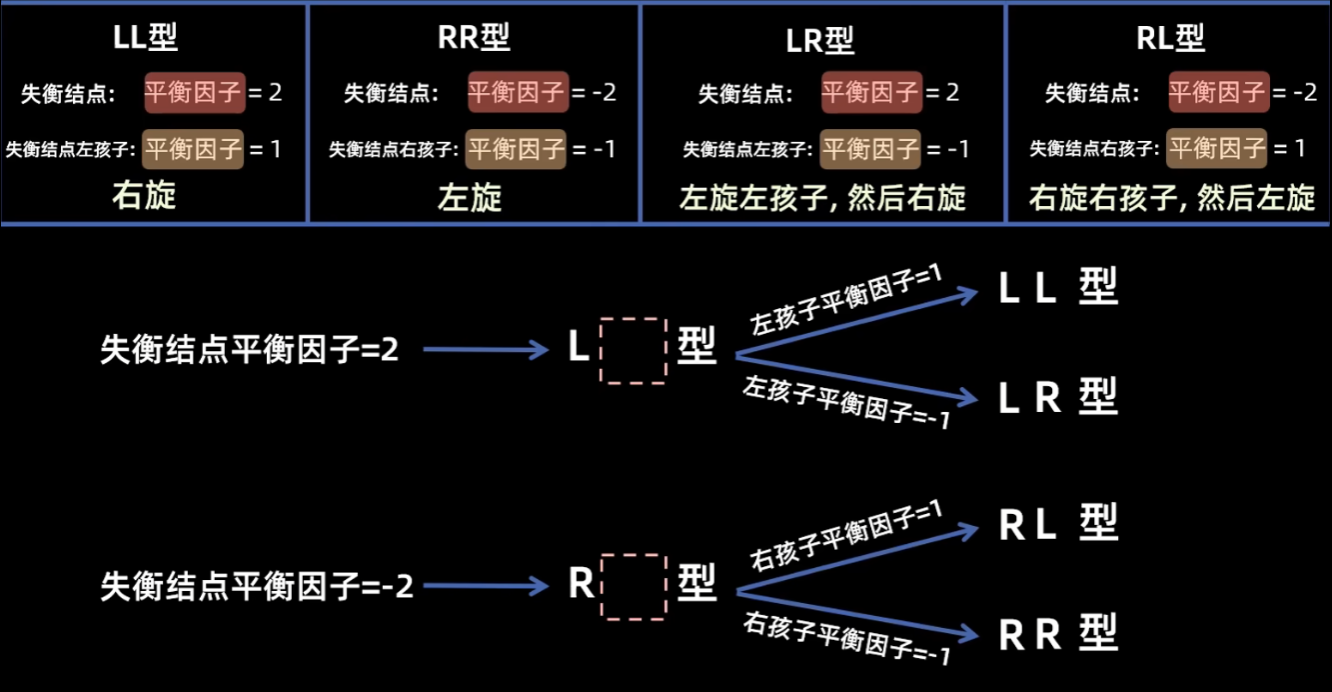
2.2.7 平衡树
用于优化二叉搜索树。有两个操作,左旋和右旋,将时间复杂度优化为$O(\log_2n)$.
平衡因子:(左子树的高-右子树的高)的绝对值。
目的:维护平衡因子小于等于1

2.2.8 图
概念
顶点:图上的每一个点。
无向图:边没有方向。
有向图:边有方向。
边:顶点与顶点之间的连线。
权:边的数值。
无向完全图:在无向图中,边数达到$n(n-1)/2$的图。
有向完全图:在有向图中,边数达到$n(n-1)$的图。
稀疏图:在$n$个顶点,$e$条边的图中,满足$e<n\log_2n$的图。
稠密图:在$n$个顶点,$e$条边的图中,满足$e\geq n\log_2n$的图。
子图:假设$G=(V,{E}),G_2=(V_2,{E_2})$,如果$V_2\subseteq V \text{且} E_2\subseteq E$,则$G_2$为$G$的子图。
领接点:两个顶点之间有一条边则为领接点。
出度、入度。
连通图:无向图中,任意两个顶点之间有路径,则为连通图。
连通分量:无向图中,极大连通子图称为连通分量。
强连通图:有向图中,任意两点连通。
强连通分量:有向图中,极大连通子图。
生成树:包含全部$n$个顶点并有$n-1$条边的连通树。
生成森林:非连通图中所有生成树组成的非连通图。
2.2.9 偶图(二分图)
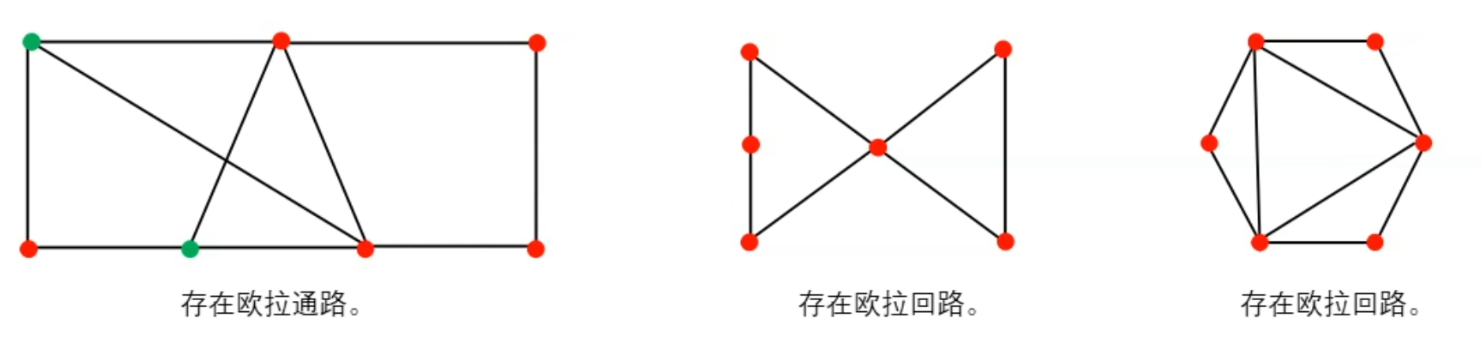
2.2.10 欧拉图
定义:$G=(V,E)$是一个无向图,$G$中一条经过图中每个边一次且仅一次的通路称为欧拉通路;若一条欧拉通路是一条回路,则称为欧拉回路。
定理:一个图有欧拉回路 <=充要=> 一个图没有奇数度的顶点。
一个图有欧拉通路 <=充要=> 一个图有且仅有两个奇数度的顶点(那两个顶点为通路的头和尾)。
2.2.11 拓扑排序
对于一个有向无环图,每次将入度为0的点加入答案队列并删除这个点及其出边。
拓扑排序可能有多重排法。
如果一个图无法拓扑排序:则说明图中有环。
2.2.12 哈希表
将一个字符串(或数组)用函数$f$表示,用两个函数值判断是否相等。
构造
对于一个字符串$s$(长度为$l$),$s$中最大ASCLL码为$b$,模数为$M$. $$ f(s) = \sum^l_{i=1}{s_i*b^{l-i}\mod M} $$ 如果出现hash重复的情况适用双哈希。
3.1 算法策略
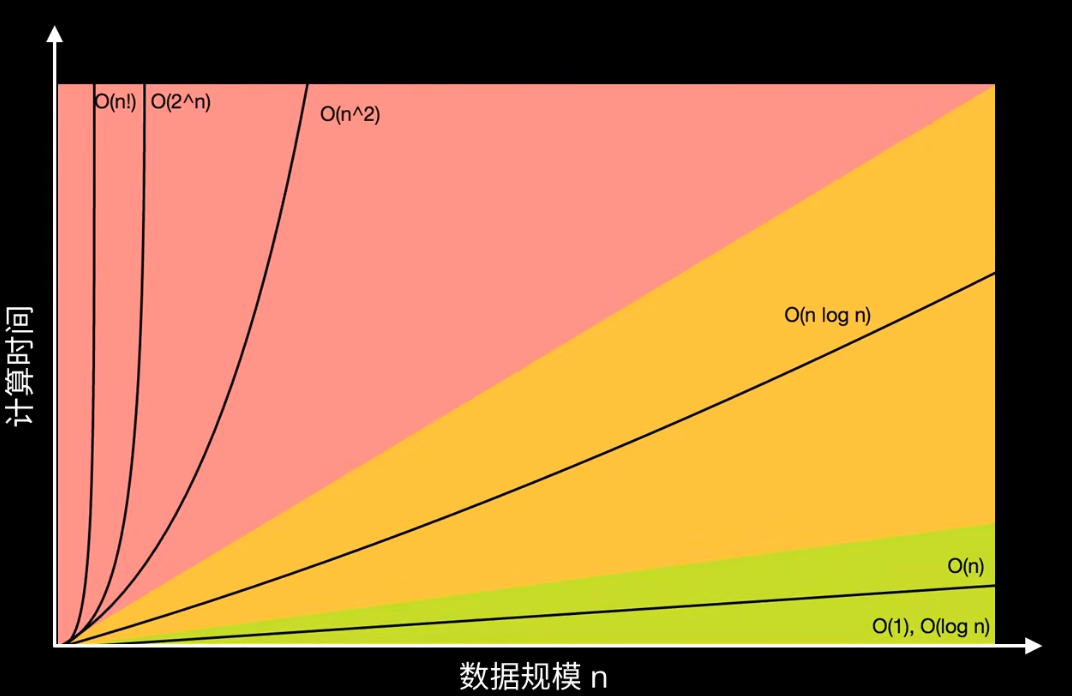
3.1.0 时间复杂度
时间复杂度和空间复杂度是衡量一个算法效率的重要标准。
3.1.1 离散化
对于一个数组$A$,$A_i$很大,但$i$很小,且程序本身只考虑相对大小不考虑绝对大小时,可以实用离散化:
即将每一个$A_i$用一个很小的$B_i$代替:
- 排序$A_i$中的元素;
- 将$A_i$对应当前排序后下标$B_i=j$;
- 输出时使用二分查找$B$中$A_i$真实大小
3.1.2 扫描线
用一条线在一个平面中扫来扫去,用于快速计算图形面积、周长等问题。(常与离散化一起使用)

3.1.3 分治思想
把大问题用递归分解成小问题直接解决:
- 分解:将问题分解成若干规模更小的子问题。
- 求解:递归求解每个子问题。
- 合并:将各个子问题合并。
3.2 排序算法
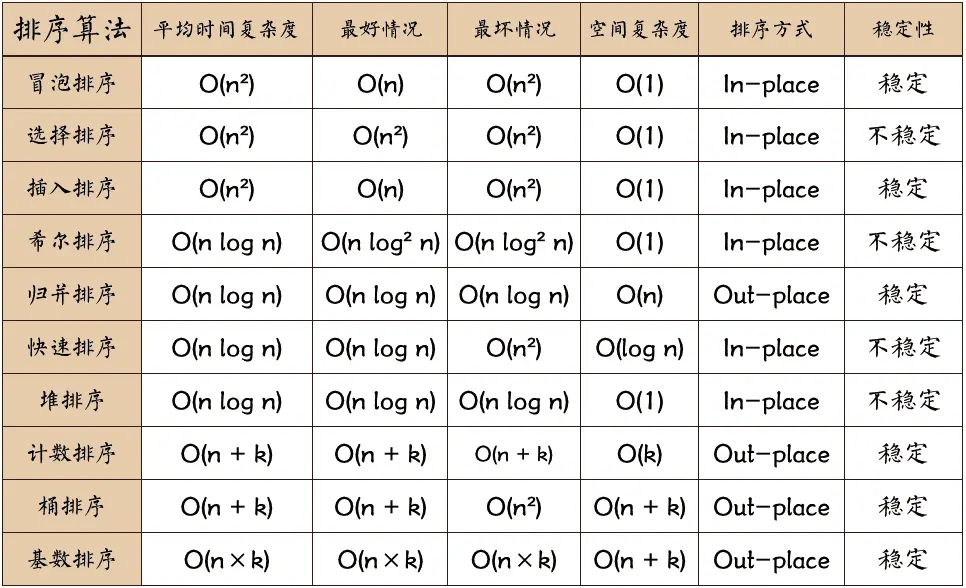
3.2.1 归并排序
使用分治思想,将数组分解,然后在合并中排序。
时间复杂度$O(\log_2 n)$
稳定排序。
3.2.2 快速排序
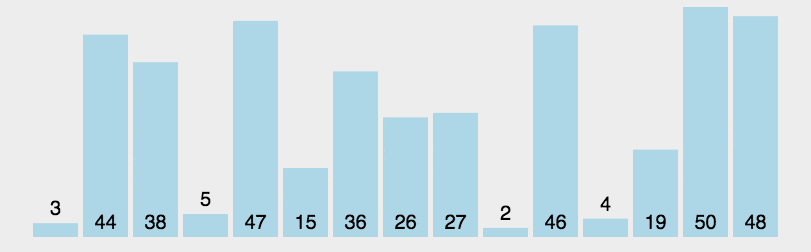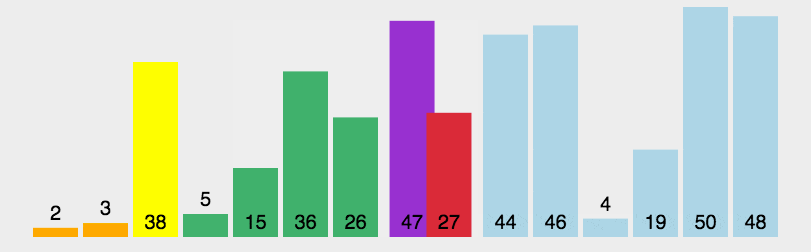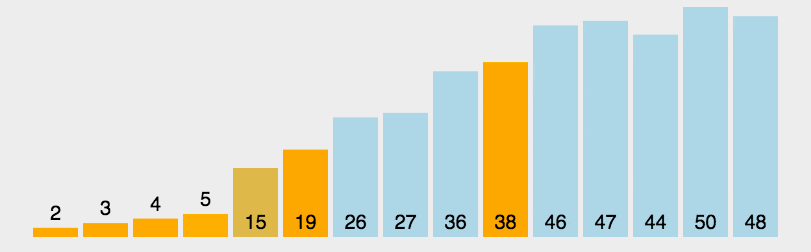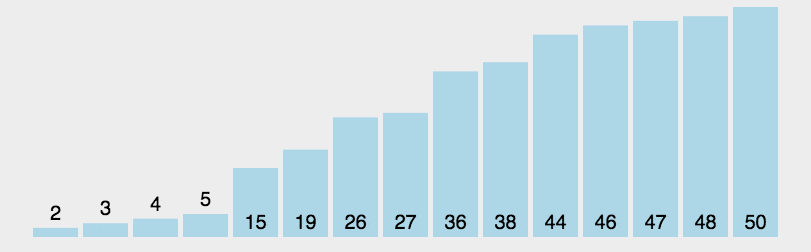
对于一个区间,找到一个中间值$mid=a_l$(可以为第一个、最后一个、或随机某个)(这时$a_l$空出),使用两个指针向中间扫描,如果$a_r$空余:当$a_l>mid$时与$a_r$交换,如果$a_l$空余:当$a_r>mid$时与$a_l$交换。
最慢时间复杂度:$O(n^2)$
最快时间复杂度:$O(n \log_2 n)$
平均时间复杂度(使用随机选择中间值):$O(n \log_2 n)$
不稳定排序。
3.2.3 堆排序
维护一个堆(priority_queue),每次添加入一个,最终输出。
时间复杂度:$O(n \log_2 n)$
不稳定排序。
3.2.4 桶排序
制造一个数组,将tong[a[i]]++,最终遍历数组输出。
时间复杂度:$O(n+k)$
稳定排序。
3.2.5 基数排序

按位数切割成不同的数字,然后每个位数分别进行排序。
时间复杂度:$O(n+k)$
稳定排序。
3.3 字符串算法
3.3.1 KMP算法
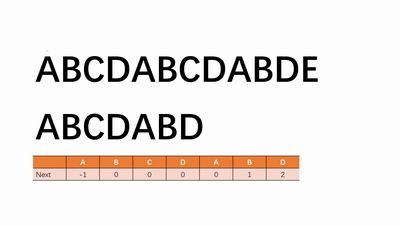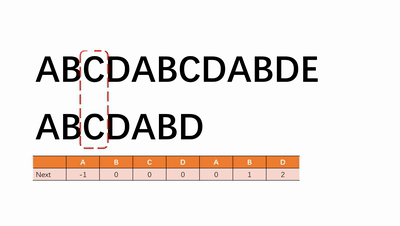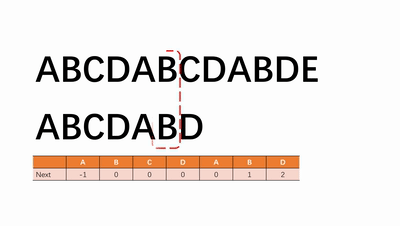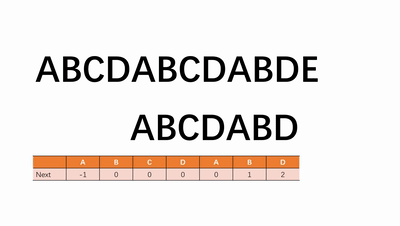
使用next数组优化暴力搜索,搜索错误只需跳转到next位置不需要重新搜索。使时间复杂度降到$O(n+m)$
3.3.2 Manacher
给定一个长为$n$的字符串$s$,请找到最长连续回文子串的长度。
Manacher算法使用了回文字符串中对称的性质,优化了原来$O(n^2)$的暴力。
cabacabad
如上字符串,已知第一个b和中间c的子串长度后,由于以c为中心的回文串左右对称,所以当以第二个b为子串中心时可以直接等于以第一个b为中心的长度。
因为回文串有两种样式(长度为单,或双),我们将每个字母中间添加任意其他字符,使所有回文串都是有一个中心的单数长度串(原双数长度子串因为中间两个字符有另一个字符,所以以这个字符为中心)。
void Manacher(string s){ // 洛谷模板题,s为小写字母
a[++n]=28;a[++n]=28;
for(int i=0;i<int(s.size());i++){ // 初始化这样的串,这里用int数组代替
a[++n]=int(s[i]-'a'+1);
a[++n]=28;
}
int j=0;
for(int i=1;i<=n;i++){
int h1=1;
if(h[j]+j>i) // 核心优化代码
h1 = min(h[j-(i-j)],h[j]+j-i);
while(a[i-h1]==a[i+h1] and h1+i<=n and i-h1-1>=0){ // 暴力搜索代码
h1++;
}
h[i]=h1;
if(h[j]+j<i+h[i]){
j = i;
}
ans = max(ans,h[i]-1);
}
return ans;
}
3.4 搜索算法
3.4.1 搜索剪枝
搜索时将不必要的方案在还未完全搜完时直接停止,剪去不必要的搜索。当要搜索很多次参数答案都相同的时候使用记忆化算法,将第一次搜索的答案存储在一个数组中,后续调用时直接访问数组获取答案,不需要重新再次计算。
3.4.2 启发式搜索
对于所有待访问的点,计算出最有可能先到达终点的点进行运算,提高搜索成功概率。
3.4.3 双向广度优先搜索
双向同时开始进行搜索,如果两端相遇,那么可以认为是获得了可行解。
3.4.4 迭代加深搜索
是一种每次限制深度的深度优先搜索,用于优化BFS队列的空间复杂度。
3.5 图论算法
3.5.1 最小生成树
Kruskal 算法
用贪心的方法,每次选取权最低且满足条件的边加入,将两颗树合并成一颗。
使用快排$O(m\log_2 m)$+并查集$O(m \log_2 n)$,就可以得到时间复杂度为:$O(m\log_2 n)$的Kruskal算法。
Prim 算法
与Kruskal算法相似,将加边改成贪心加点,并加上类似Dijkstra的堆优化。
使用二叉堆时间复杂度:$O((n+m)\log_2 n)$
3.5.2 单源最短路
Bellman-Ford
支持负权边,查找负权环等问题。
松弛操作:对于一条边$(u,v)$:
$$
dis(v)=min(dis(v),dis(u)+w(u,v))
$$
一直进行这样的松弛操作,直到dis数组没有修改(收敛),或是一直进行修改(负权环)。
时间复杂度:$O(nm)$
Dijkstra
使用贪心思路,并用优先队列优化,每次查询当前分数最小的点.
时间复杂度$O(n\log_2 n)$.
无法支持负权边,或负权环。
3.5.3 单源次短路
基于单源最短路,额外追加追踪次短路的长度。
3.5.4 Floyd
用于解决多源最短路问题,时间复杂度$O(n^3)$
可以处理负权,但不能处理负权环。
转移思想:以中间节点为桥梁,连通两边节点。 $$ f_{i,j}=min(f_{i,j},f_{i,k}+f_{k,j}) $$
3.5.5 强连通分量
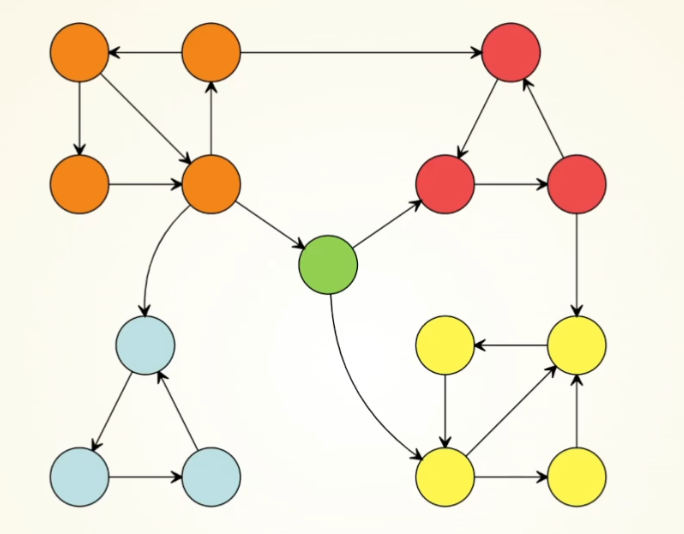
如图,使用塔尖算法计算强连通分量(有向图中,强连通分量内任意两点一定可以互相到达,相同颜色的点为强连通分量)。便于题目后续计算。
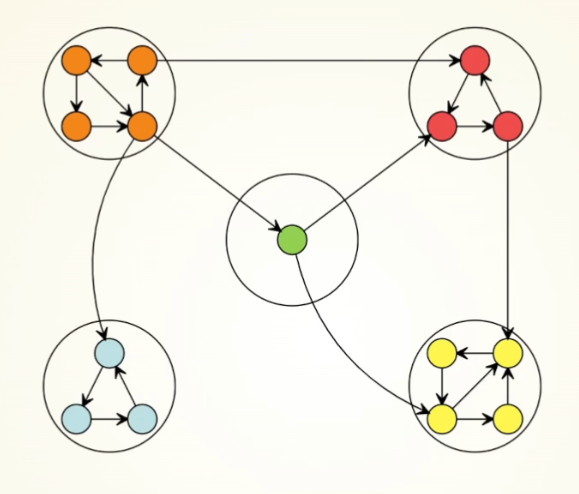
- 使用dfs,将有向图划分成一颗树,用栈记录当前访问节点。
- 在树边之外加上若干额外边,从额外边向前推,并弹出栈。
弹出的元素即为当前强连通分量中的点。
3.5.6 割点和桥
割点:在无向图中,去掉某个点及其边后图不再连通。
桥:在无向图中,去掉某条边后图不再连通。
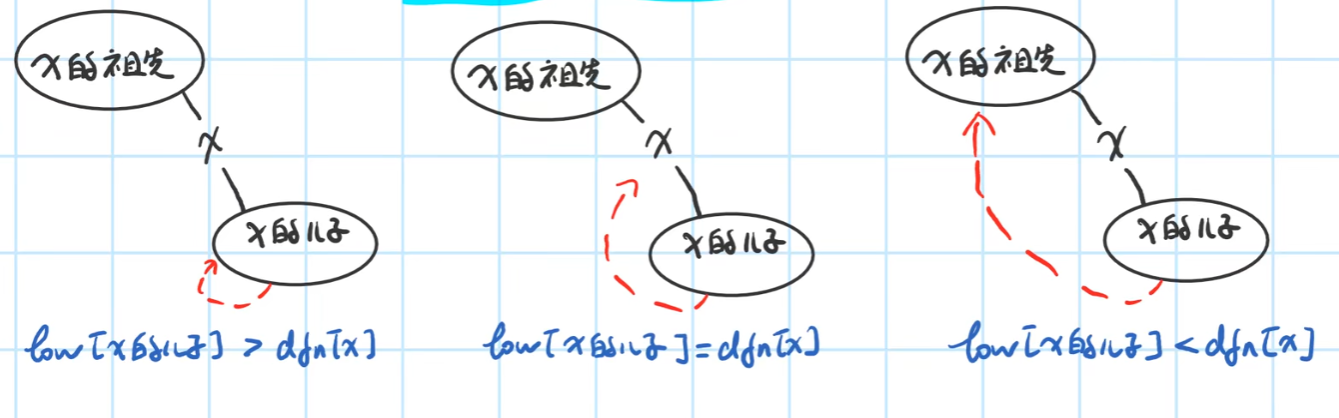
如图,在塔尖dfs搜索时,出现这三种情况,则第一种第二种x是割点,第三种不是。
3.5.7 树的重心
对于一颗树,以某个点为跟节点时,最大子树的节点数最少,那么这个节点时重心。
对于一个重心,每个子树的节点数不超过总节点数的一半,所有节点都走向重心。
一棵树最多有两个重心,且相邻。
使用树形DP实现,记录「向下」的子树的最大大小,利用总点数减去当前子树的大小。
3.5.8 树的直径
直径:从叶子节点出发向上到达另一个叶子节点
dfs:返回当前节点为根时子树的最长链=max(dfs左,dfs右)+1
3.5.9 最近公共祖先
用一个数组f[i][j]记录第$i$个节点第$2^i$个父节点是谁;用h[i]记录第$i$个节点的深度。
- 深度大的节点找到和另一个节点同深度的节点。
- 重复执行,从最大的$i$递减搜索,前$2^i$的父节点是否相同,不同则同时向前调到这个节点,相同则不处理。
- 最后两个节点的父节点为最近公共祖先。
时间复杂度:$O(n\log_2n)$.
3.6 动态规划
动态规划本质上使用字典/哈希表等方式保存计算结果,以达到优化时间的目的。从递归也可以改成迭代形式。
3.6.1 树形动态规划
顾名思义,如前面重心和直径问题一样,动态规划在树上进行,递归树上的点,得到答案。
3.6.2 动态规划优化
空间:使用bitset,或直接使用二进制int,存储一维的dp数组,优化空间。
时间:如果需要动态区间操作:树状数组和线段树有效优化了时间复杂度。
减去不必要的搜索,去除冗余。
4.1 初等数论
4.1.1 最大公约数
gcd(a, b) = gcd(b, a % b)
当b=0时a为最大公约数。
4.1.2 同余式
$$ a\mod n = z $$
$$ b\mod n=z $$
我们称:$a \equiv b \pmod{n}$
也可写成:$a=kn+b$
4.1.3 欧拉函数
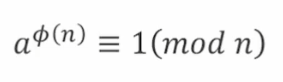
$\phi(n)$表示${1,2,3,...,n}$内与$n$互质的个数。
即:$\phi(n)=满足1≤k≤n且\gcd(k,n)=1的整数k的个数$
4.1.4 费马小定理
如果p是一个质数,而整数a不是p的倍数,则有a^(p-1)≡1(mod p)。

4.1.5 威尔逊定理
对于任意素数p,有: $$ (p−1)!≡−1(\mod p) $$
4.1.6 裴蜀定理
$a,b$互质 <==> 存在整数$x,y$使$ax+by=1$
4.1.7 模逆元 - 扩展欧几里得
又称数论倒数,当gcd(a,p)=1,满足: $$ ax≡1\pmod{p} $$ 扩展欧几里得: $$ ax-pn=1 $$
4.2 离散与组合数学
4.2.1 多重集合
(multiset),可以重复出现元素的集合。